Article •
What the Hell is Attention
Okay. So we all know what a context window is and what prompting is but I tried diving really deep into the foundation of how all our favourite models actually work. A very human attempt to understand "Attention Is All You Need"
Attention Is All You Need (And I Needed A Lot Of It)
I am sure many of us have heard of the infamous Google paper, "Attention Is All You Need", that birthed the LLM architecture. In my pursuit of a non-wasted Saturday I attempted to understand it, I will try to explain it here but I must confess - not everything was entirely clear to me and will likely require a second (...third, forth,...,tenth) pass over.
It begins with a word, or rather a token.
You see when a model processes a sentence, it breaks it up into tokens. For example:
"I love doughnuts" gets broken into:
["I", "love", "doughnuts"]A token is roughly a word but it can be half a word:
["I", "love", "dough", "nuts"]This happens because tokenization uses a fixed algorithm built on common language patterns so unusual or rare words get carved up because the tokenizer simply has no single token for them. "Doughnuts" might survive intact. A word you invented (i.e taxes) definitely won't.
So okay, the model has its tokens. But what does it do with them?
How does it gather that this man, with a stomach that could be flatter and a sweet tooth to worry any dentist, loves doughnuts?
Well, it plots the tokens on a graph.
Each token gets converted into a list of numbers — called a vector — and this vector is its address in a vast mathematical space. We call this an embedding.
"I" → [0.1, 0.2]
"love" → [0.9, 0.8]
"doughnuts" → [0.8, 0.7]
"taxes" → [0.1, 0.1](Real vectors have hundreds of dimensions, not two but the idea is the same)
Words that are similar in meaning end up living near each other in this space:
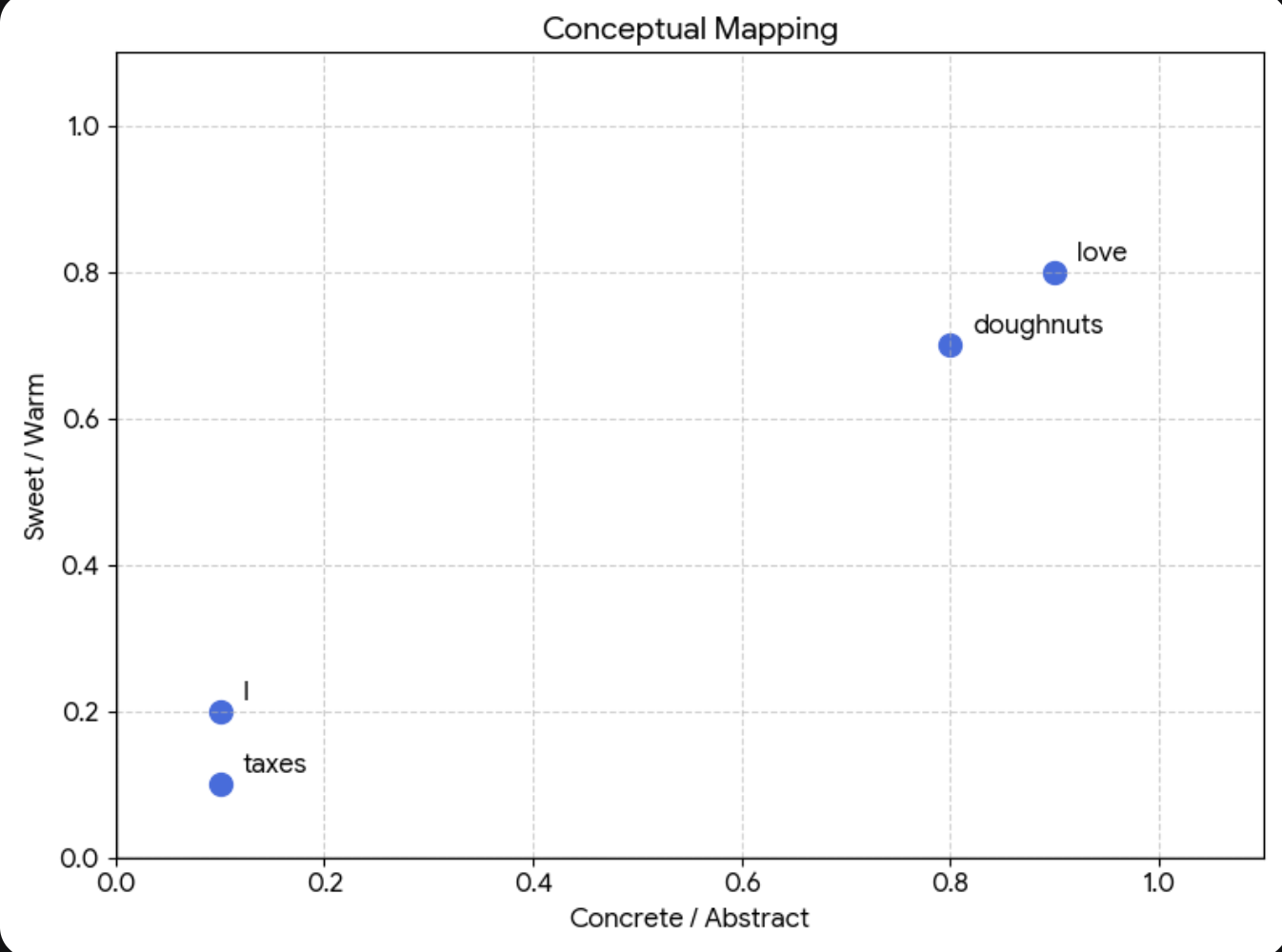
"Doughnuts" and "love" are neighbours. "Doughnuts" and "taxes" are not. The model knows what each word means — roughly — by knowing where it lives.
But here's the problem.
The model has no idea that "love" came second. It sees three addresses in a city but doesn't know the order you visited them. And order matters enormously:
Same tokens. Very different evenings.
So the model adds a positional encoding to each token's vector a small mathematical signal that says: you were first, you were second, you were third.
Now the model knows both what the words mean and where they sat in the sentence.
Now comes the thing the paper is actually named after. The thing that changed everything.
Attention.
When the model is processing any single token, it doesn't just look at that token in isolation. It looks at every other token in the sentence and asks: how relevant is each of these to understanding what I'm currently looking at?
To do this, each token gets transformed into three separate vectors:
Every token has all three. The Query of one token gets compared against the Keys of every other token using a dot product multiply matching positions, add them up:
Higher number = stronger match = more attention paid. The model then converts these raw scores into weights that sum to 1 a process called softmax:
Now the model uses these weights to take a weighted mix of the Values:
The result is a new, richer vector for the token being processed, one that has absorbed information from the tokens that mattered most. "Doughnuts" now carries the flavour of "love." The model is starting to understand the sentence.
Now here's where it gets clever.
The model doesn't run this attention process just once. It runs it several times in parallel, each time with different Query/Key/Value setups. Each one learns to notice different kinds of relationships:
This is Multi-Head Attention. Like having several readers go through the same sentence, each underlining different things, then comparing notes. Their findings get concatenated and combined:
Now, there's one more piece of the architecture worth knowing — the Encoder/Decoder structure.
The Encoder takes your input and runs it through everything we just described — embeddings, positional encoding, multi-head attention — until it has built a deep, contextualised understanding of what the input means.
The Decoder then generates the output one token at a time, attending at every step to both the encoder's understanding and what it has already written:
So why did this matter so much?
Before this paper, the dominant architecture was something called an RNN a Recurrent Neural Network. RNNs read sentences word by word, in sequence, like this:
By the time they reached the end of a long sentence, they had often half-forgotten the beginning. Information decayed. Context was lossy.
Attention solved this. Every token can look directly at every other token simultaneously, regardless of distance:
That's the revolution. Not just better performance — a fundamentally different way of reading.
I will be honest with you. I read this paper on a Saturday and I still don't feel like I've fully earned the right to explain it. There are mathematics behind the attention scores scaling factors, full matrix multiplications that I have graciously chosen not to subject either of us to today.
But the shape of it, I think I have. Tokens become vectors. Vectors get positioned. Attention decides what matters. Multiple heads find multiple things that matter. Encoder understands. Decoder speaks.
And somewhere in all of that machinery, the model knows that I — stomach and all — love doughnuts.
Next week I will either do a second pass on the mathematics, or I will eat a doughnut and call it research. Possibly both.
But here's the problem.
The model has no idea that "love" came second. It sees three addresses in a city but doesn't know the order you visited them. And order matters enormously:
"dog bites man" ≠ "man bites dog"Same tokens. Very different evenings.
So the model adds a positional encoding to each token's vector a small mathematical signal that says: you were first, you were second, you were third.
"I" → [0.1, 0.2] + position 1 signal → [0.2, 0.3]
"love" → [0.9, 0.8] + position 2 signal → [0.9, 0.9]
"doughnuts" → [0.8, 0.7] + position 3 signal → [0.7, 0.8]Now the model knows both what the words mean and where they sat in the sentence.
Now comes the thing the paper is actually named after. The thing that changed everything.
Attention.
When the model is processing any single token, it doesn't just look at that token in isolation. It looks at every other token in the sentence and asks: how relevant is each of these to understanding what I'm currently looking at?
To do this, each token gets transformed into three separate vectors:
For "love":
Query → [0.9, 0.2] (what am I looking for?)
Key → [0.7, 0.5] (what do I contain?)
Value → [0.8, 0.6] (what will I give away?)Every token has all three. The Query of one token gets compared against the Keys of every other token using a dot product multiply matching positions, add them up:
"love" Query [0.9, 0.2] vs "doughnuts" Key [0.8, 0.3]:
(0.9 × 0.8) + (0.2 × 0.3) = 0.72 + 0.06 = 0.78 (high match!)
"love" Query [0.9, 0.2] vs "I" Key [0.1, 0.9]:
(0.9 × 0.1) + (0.2 × 0.9) = 0.09 + 0.18 = 0.27 (low match)Higher number = stronger match = more attention paid. The model then converts these raw scores into weights that sum to 1 a process called softmax:
Raw scores: "I" = 0.27, "love" = 1.0, "doughnuts" = 0.78
After softmax: "I" = 0.15, "love" = 0.50, "doughnuts" = 0.35
↑ most attention hereNow the model uses these weights to take a weighted mix of the Values:
Final output = (0.15 × Value of "I")
+ (0.50 × Value of "love")
+ (0.35 × Value of "doughnuts")The result is a new, richer vector for the token being processed, one that has absorbed information from the tokens that mattered most. "Doughnuts" now carries the flavour of "love." The model is starting to understand the sentence.
Now here's where it gets clever.
The model doesn't run this attention process just once. It runs it several times in parallel, each time with different Query/Key/Value setups. Each one learns to notice different kinds of relationships:
Head 1 → tracks grammar: "love" → verb → connects to subject "I"
Head 2 → tracks meaning: "love" → sentiment → connects to "doughnuts"
Head 3 → tracks position: what came before? what comes after?This is Multi-Head Attention. Like having several readers go through the same sentence, each underlining different things, then comparing notes. Their findings get concatenated and combined:
Head 1 output: [0.8, 0.3]
Head 2 output: [0.6, 0.9]
Head 3 output: [0.4, 0.7]
Combined: [0.8, 0.3, 0.6, 0.9, 0.4, 0.7]
↓
passed through one more transformation
↓
final rich representation of the tokenNow, there's one more piece of the architecture worth knowing — the Encoder/Decoder structure.
Input sentence Output sentence
"Je t'aime les beignets" ↓
↓ "I love doughnuts"
[ ENCODER ] →→→→→→→ [ DECODER ]
reads & understands generates, one token
the whole input at a timeThe Encoder takes your input and runs it through everything we just described — embeddings, positional encoding, multi-head attention — until it has built a deep, contextualised understanding of what the input means.
The Decoder then generates the output one token at a time, attending at every step to both the encoder's understanding and what it has already written:
Step 1: encoder output + "" → predicts "I"
Step 2: encoder output + "I" → predicts "love"
Step 3: encoder output + "I love" → predicts "doughnuts"
Step 4: encoder output + "I love doughnuts" → predicts [END]So why did this matter so much?
Before this paper, the dominant architecture was something called an RNN a Recurrent Neural Network. RNNs read sentences word by word, in sequence, like this:
"I" → [memory] → "love" → [memory] → "doughnuts" → [fading memory of "I"]By the time they reached the end of a long sentence, they had often half-forgotten the beginning. Information decayed. Context was lossy.
Attention solved this. Every token can look directly at every other token simultaneously, regardless of distance:
RNN: I → → → love → → → doughnuts
(forgot "I" a bit)
Attention: I ←————————————→ doughnuts
I ←————→ love
love ←——→ doughnuts
(everyone sees everyone, instantly)That's the revolution. Not just better performance — a fundamentally different way of reading.
I will be honest with you. I read this paper on a Saturday and I still don't feel like I've fully earned the right to explain it. There are mathematics behind the attention scores scaling factors, full matrix multiplications that I have graciously chosen not to subject either of us to today.
But the shape of it, I think I have. Tokens become vectors. Vectors get positioned. Attention decides what matters. Multiple heads find multiple things that matter. Encoder understands. Decoder speaks.
And somewhere in all of that machinery, the model knows that I — stomach and all — love doughnuts.
Next week I will either do a second pass on the mathematics, or I will eat a doughnut and call it research. Possibly both.